卡尔曼滤波(Kalman Filter)
卡尔曼滤波(Kalman Filter)
卡尔曼滤波器的背景
火箭在发射过程中需要时刻预测自己的状态(此处所述的状态包括火箭的位置与速度),对于火箭的状态数据可以通过一些传感器来获取这两个测量,但是由于存在电离层和大气干扰,传感器的测量值有时误差会比较大,这样就需要通过一种方法来预测一个新的更加准确的、且不完全依赖传感器返回值的状态信息。
在事实上,如果传感器的返回值(对于火箭状态数据的观测数据)非常离谱,那么就有理由不相信此时的数据,因为火箭运动需要符合一定的运动方程,即使存在干扰,误差以及火箭发射过程中实际场景中的一些问题,火箭状态的观测数据也应该在一定的误差范围之内。
卡尔曼滤波的初步思路
这样就有一个合理的思路:将状态观测数据与理论预测数据进行加权平均。这样就可以既不完全相信传感器,也不完全相信理论模型。
上式中,\hat{x}_{n,n-1}是根据前n-1个时刻预测得到的第n个时刻的预测值,z_n是n时刻的观测值。
上式的意思就是对于第n个时刻数值的估计,通过\hat{x}_{n,n-1}与z_n进行加权平均来获取,这个权重就是\alpha_n。
那么现在的问题就是如何确定这个\alpha_n。
一维卡尔曼滤波器
卡尔曼滤波器的维度是根据系统所需要的采集数值的数量(如,在车辆形式过程中需要采集车辆的瞬时速度,那么就需要一个预测过程和一个观测过程进行一个一维数值的采集。如果对于车辆形式过程中需要采集车辆的瞬时速度与车辆的位移距离,那么就需要通过两个预测过程与两个观测过程进行数据的采集)
由于理论模型(也就是系统的预测方程,所述的预测方程即为对系统中所需观测数值的描述,可以是一个车辆形式过程中的位移与速度之间的方程关系,也可以是一个预测模型的预测方程)和观测过程(观测过程即为通过传感器对所需数据进行实时的采集,即为观测)都是存在相应的干扰的,此处,==假设二值均服从正态分布==
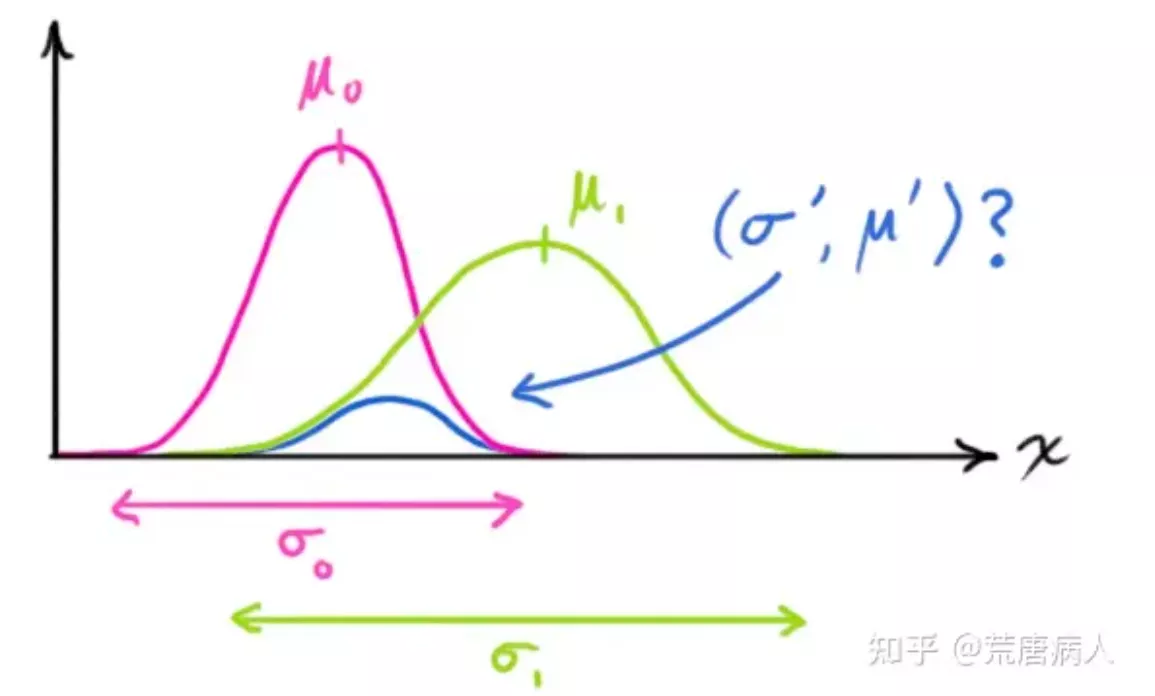
在上图中,红色的数值分布为预测数值的分布,绿色为观测数值的分布。(预测数值也是一个概率分布,这是因为理论模型肯定不能与实际情况完全符合)所以采集的数值应该是结合红线与绿线的分布,即像蓝色分布那样。
如果只考虑分布的均值\mu,一个很直观的思路就是预测数值的分布与观测数值的分布,哪个变化的更平稳,也就是方差越小,则该分布对应的数值的可信度就越高,==方差越小,权重越高==,与此同时保证总权重为1即可:
上式中的权重分母仅代表二者权重和为一,通过softmax进行归一化也可以达到效果。
那么上式即为,假设\mu_0为预测值,\mu_1为观测值,则\alpha = \frac{\sigma_0}{\sigma_0 + \sigma_1}
上述的过程中是通过一个简单直观的逻辑进行权重的确定。现在尝试用一种更符合数学逻辑的思路:==希望新的值得不确定程度最低,即使得新的值得方差取最小值==(为达到这个目的,就需要计算融合结果得方差表达式,并使导数为0)
设x,y是两个概率分布,并且有y=ax,那么二者得方差之间存在关系\sigma_y = a^2\cdot \sigma_x
等号两侧同时对\alpha求导,并使其为0:
可以解得:
可以发现这样算出来得答案与之前得想法相同。
经过上述过程,现在可以通过\sigma_0,\sigma_1计算权重\alpha了,那么应该如何获取\sigma_0,\sigma_1?
理论模型值得概率分布和观测值的概率分布只能通过大量数据采样得到,这要求我们在应用上述方法进行滤波前,应该通过大量观察对理论模型和观测数据的分布有一个准确的了解。实际工程我们一般假设传感器是具有某个确定分布的,这个分布可以对传感器进行一段时间的观测得到(如slam中经常会让系统静止两小时,从而计算传感器的分布)。而系统的方差是会随着我们每一次进行Kalman融合而改变的(因为状态矩阵a的影响),我们需要持续的计算系统方差--迭代。
在系统的运行开始后,我们能做的就是计算每一次的理论值方差,根据这个方差和传感器方差计算出融合权重,并且在每一次获取数值之后都要重新计算,这个就是迭代过程。
计算\sigma_x,\sigma_z
在上述过程中,没进行一次观测,就需要对两个分布的方差重新进行计算(一般传感器方差不重新计算,将传感器方差设为固定值),迭代下去,为了表示清晰使用\sigma_x替换\sigma_0,\sigma_z替换\sigma_1
因为是迭代的过程,考虑第k个时刻,当前的最优估计值应该由根据之前时刻状态由运动模型计算出来的预测值,和t_k时刻的传感器测量值,融合计算出t_k时刻的kalman估计值。
所以将上述的\sigma_x,\sigma_z变为\sigma_{x,t-1},\sigma_{z,t},代表由第t-1时刻的状态计算的x的理论值的方差,和t时刻的测量值的方差。
在这里统一一下,之后所有的公式中\hat{x}代表kalman理论最终预测值,x代表由运动模型,即状态方程更新得到的值,x后文会以理论值代称,\hat{x}后文会以预测值代称。
传感器测量值的分布一般可以当作已知(传感器噪声一般都是符合某个均值为0的固定分布的),因此只需要计算\sigma_x。
状态更新方程
当我们得到的t时刻的kalman估计值,需要引入状态更新方程,得到新的预测值,同时计算预测值的方差。
上式中b是控制信号(设为常数),\sigma_q是理论模型的误差的方差。(理论模型的误差的)
x_{t,t-1}是预测方程通过t-1时刻的数值预测得到的t时刻的预测值。
\hat{x}_{t-1,t-1}即为通过卡尔曼滤波获取到的t-1时刻理论值。
这里需要注意的是,状态更新每次都需要上一时刻的真实状态作为输入,而我们是无法确定一个客观绝对真实的输入,所以就只能拿上一个时刻由kalman理论预测出来的\hat{x}_{t-1}作为输入计算理论值。也就是将卡尔曼滤波过程获取到的上一个时刻的理论值看作是一个真实值。
至此,计算出了\sigma_x,\sigma_z,其中\sigma_z是先验设定的,那么就有了下面的四个式子:
上式中z为观测值。k_t即为t时刻对应的卡尔曼增益(也就是观测值的权重),而1-k_t就是预测值的权重。
由\hat{x}_{t} = (1-k_t)x_{t-1} + k_tz_t,有:\sigma_{\hat{x},t} = (1-k_t)^2\sigma_{x,t-1} + k_t^2\sigma_{z,t}
将k_t = \frac{\sigma_{x,t-1}}{\sigma_{x,t-1}+\sigma_z}代入该式,有:
观测矩阵H
与此同时,实际模型中的观测值一般不是状态变量,二者会存在一定的关系:???
这里的x'_{t,t}是得不到的绝对真实值(卡尔曼滤波就是为了让\hat{x}_{t,t}接近x'_{t,t})这个式子的目的主要是为了得到h^{-1},因为往往观测值和状态变量维度不一致,或者量纲不一样,所以需要这个h使得二者可以相加。
这里缺少一个h存在对应的实际原因,后续补充
则由:\hat{x}_{t,t} = (1-k_t)x_{t,t-1}+\frac{1}{h}k_tz_t
令该式中的\frac{k_t}{h} = K_t则有:
那么\sigma_{x,t} = (1-K_th)\sigma_{x,t-1}
至此,得到了一维卡尔曼滤波器的五个方程
- 状态外推公式
- 协方差外推公式
- Kalman增益计算公式
- 融合公式(状态更新公式)
- 协方差更新公式
一维卡尔曼滤波拓展到多维卡尔曼滤波器
所谓的一维到多维的拓展就是用协方差矩阵P替换\sigma
协方差矩阵就是多维情况下的方差,直接用P替换\sigma即可(H为方阵时,不为方阵的情况需要额外说明)
此外,a^2变为AxA^T,这是因为,矩阵的形式中,若是需要每一个元素x乘以a^2,就要写成这个形式。R即为所说的\sigma_z对应的协方差矩阵。
- Kalman滤波器具有markov性质,也就是通过上一时刻的预测数值与观测数值通过卡尔曼增益的形式对当前时刻的观测数值与上一时刻的预测数值之间进行权衡,卡尔曼增益在迭代的过程中也包括了全部的历史信息,因此不是简单的从上一时刻预测下一时刻。
- Kalman滤波器更像是一个做融合问题的方法,而不是预测,其对传感器有一定的要求,传感器的误差均值应该为0才可以通过卡尔曼滤波器获取到更好的效果。
- 出了状态外推方程之外,Kalman滤波器的变量就只剩下了Q和R,Q为预测过程的不确定性,R为观测用的传感器的不确定性。