无监督的数据异常检测算法(1)- LOF
无监督的数据异常检测算法(1)- LOF
1.1 LOF简介
在众多的离群点检测方法中,LOF方法是一种典型的基于密度的高精度离群点检测方法。在LOF方法中,通过给每个数据点都分配一个依赖于邻域密度的离群因子LOF,进而判断该数据点是否为离群点。若LOF\gg1,则该数据点为离群点;若LOF接近于1,则该数据点为正常数据点。
1.2 距离度量尺度
设对于没有相同点的样本集合D,假设共有n个检测样本,数据维数为m,对于
针对数据集D中的任意两个数据点X_i,X_j,存在如下几种常用的距离度量方式:
- Euclid距离(欧几里得距离)
- Hamming距离(汉明距离)==汉明距离使用在数据传输差错控制编码里面,用于度量信息不相同的位数==
- Mahalanobis距离(马氏距离)
- 球面距离
- 除上述之外,还有切比雪夫距离,闵可夫斯基距离,绝对值距离,曼哈顿距离等,根据具体问题具体分析选择哪一种距离度量方式
在下述内容中统一使用d(A,B)表示点A和点B之间的距离。根据定义,可以根据交换律得d(A,B)=d(B,A)
1.3 LOF计算步骤
1.3.1 第k距离
d_k(O)为点O的第k距离,d_k(O) = d(O,P)满足如下条件
- 在集合中至少存在k个点P'\in D\{O\}使得d(O,P')\le d(O,P)
- 在集合中至多存在k-1个点P'\in D\{O\}使得d(O,P')<d(O,P)
简而言之:点P是距离O最近的第k个点

确定的k值在后续的离群点检测中十分重要,这个数值的确定表示在离群点的检测中通过带检测点周围多少个点来对其进行判断。
在确定了k的值之后,也就是确定了第k距离。因为有了第k距离从而有了**k距离邻域**
1.3.2 k距离邻域
设N_k(O)为点O的第k距离邻域,满足:
此处的邻域表示的是具体的点,这个邻域集合中包含所有到点O的距离小于点O第k邻域距离的点。
同样由第k距离得到的概念还有-可达距离
1.3.3 可达距离
以O为中心,点P到点O的第k可达距离定义为:
可达距离可以看作是一种简化,直接的衡量方式:
点P到点O的第k可达距离至少是点O的第k距离。距离点O最近的k个点,他们到O的可达距离被认为是相等的,都等于d_k(O)
通过k距离邻域和可达距离,引出了局部可达密度
1.3.4 局部可达密度
局部可达密度的定义为:
局部可达密度表示点P的第k邻域内所有点到P的平均可达距离。如果P和周围邻域点是同一簇,那么可达距离更可能为较小的d_k(O),导致可达距离之和更小,局部可达密度更大。如果点O和周围邻域点较远,那么可达距离可能会取较大值d(O,P),导致可达距离之和更大,局部可达密度更小。
通过局部可达密度引出了最终的LOF局部离群因子。
1.3.5 局部离群因子
LOF局部离群因子则是点P的邻域N_k(P)内其他点的局部可达密度与点P的局部可达密度之比的平均数。如果这个比值越接近于1,说明点O的邻域点密度差不多(相近),点O的邻域点密度差不多,点O则可能和邻域同属于一簇(不是离群点);如果这个比值小于1,则说明O的密度高于其邻域点的密度,O为局部的密集点(不是离群点);如果这个比值大与1,说明点O的密度小于其邻域点密度,点O可能是异常点。
根据局部可达密度的定义可以知道,如果一个数据点与其他点比较疏远的话,那么显然它的局部可达密度就会比较小。但是局部离群因子是通过一个数据点的局部可达密度与其k距离邻域中的数据点的局部密度比较,获得一个相对的密度。这样就可以允许数据分布不均匀,密度不同。
1.4 示例
如下图所示:
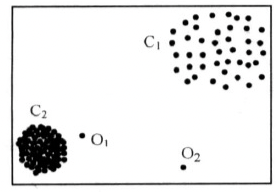
图中是一个二维数据集,图中包含两个簇C_1,C_2和两个离群点O_1,O_2,其中C_1更为稠密,C_2稀疏,O_1是局部离群点,O_2是全局离群点。如果根据全局的异常因子检测方法,O_2离群点易于挖掘,但是O_1会难以挖掘。如果为了挖掘出O_1而调整全局离群点检测的参数,那么C_1中大部分的数据点都可能会被标识为离群点。